


Super resolution is a set of techniques used to enhance the quality and detail of images beyond their original resolution. It isn’t just about making images bigger. It’s a technique of intelligently adding detail and sharpness to create a high-resolution image from one or more low-resolution inputs.
This technology has applications ranging from medical diagnostic imaging and enhancing retail surveillance footage to improving industrial inspection processes. It allows for clearer, more detailed images in challenging low-light environments common in stores, factories, and medical facilities, improving the decision-making and overall functionality of the camera.
In this blog, we explain different types of super resolution techniques, the technical steps involved in attaining super resolution, and more.
Types of Super Resolution
There are two main approaches to super resolution:
Let’s break these down and see how they work.
Classical Multi-Image Super Resolution
Multi-Image Super Resolution (MISR) is a classical technique for creating high-resolution images from multiple low-resolution ones. It leverages the subtle differences between slightly shifted captures of the same scene to extract additional detail.
The steps involved in multi-image resolution technique are given below:
-
- Image Acquisition:The process starts by capturing several low-resolution images of the same scene (Refer to Figure 1: Stages in Multi-Image Super Resolution Process). These images can be obtained in a few ways. A camera can be slightly repositioned between shots, creating a small parallax effect (shift in perspective). A video camera can also be used to capture a short burst of frames, with slight camera shake or object movement introducing the necessary variations.It’s important to note that the low-resolution images should be well-aligned and capture the scene from slightly different viewpoints. Blurry or out-of-focus images won’t contribute effectively to the result.
- Image Registration:Even with slight movements, the captured images won’t perfectly align. Registration is the process of precisely aligning these images pixel-to-pixel. Common registration algorithms use techniques like feature matching or phase correlation to find corresponding points between the images. Accurate registration is important because misalignment can lead to artifacts and blurry details in the final super-resolved image.
- Image Fusion:Once aligned, the information from each low-resolution image is combined to create a more detailed representation. This fusion process leverages the complementary information captured in each image.Different fusion algorithms exist, but a common approach is weighted averaging. Here, each pixel in the final image is a weighted combination of the corresponding pixels from the aligned low-resolution images. The weights are assigned based on factors like image quality and sharpness.
- Deblurring:The registration and fusion process can sometimes introduce blur to the final image. Deblurring techniques aim to remove this blur and sharpen the image. Common deblurring algorithms use filters or statistical models to recover the high-frequency details lost during the previous steps.
 Figure 1: Stages in Multi-Image Super Resolution Process
Figure 1: Stages in Multi-Image Super Resolution Process
Advantages and Limitations of Multi-Image Super Resolution
The Multi-Image Super Resolution (MISR) is a technique that can significantly enhance the resolution and detail compared to a single low-resolution image. It works well for static scenes with slight variations between captured images.
One major drawback of this technique is that it requires multiple low-resolution images of the same scene, which might not always be available. It is limited by the number and quality of input images available.
In this approach, the quality of the final output depends heavily on the quality and alignment of the input images. Hence, it is not effective for scenes with significant motion or object movement between captures.
Example-Based Super Resolution
Example-Based Super Resolution (EBSR) is a versatile technique that relies on a database of image pairs to enhance image resolution. This approach is more flexible, as it can work with just a single input image. It relies on a database of image pairs – low-resolution patches and their high-resolution counterparts. Unlike Multi-Image Super Resolution, EBSR can work with a single input image, making it more flexible in various applications.
Key Steps in EBSR:
-
-
- Patch Extraction: The input image is divided into smaller, overlapping patches. These patches serve as the basis for comparison with the database.
- Database Comparison: Each extracted patch is compared to the low-resolution patches stored in the database. Similarity metrics like Euclidean distance or structural similarity index (SSIM) are used to measure how closely a patch matches the database entries.
- High-Resolution Patch Selection: For each input patch, the most similar patch from the database is selected. The corresponding high-resolution patch associated with the selected database entry is then retrieved.
- Reconstruction: The high-resolution patches obtained from the database are combined to form the final super-resolved image.
-
Techniques like nearest-neighbor interpolation, bilinear interpolation, or more complex reconstruction methods can be employed to stitch these patches together smoothly.
In ESBR, the quality of the database is important. A large and diverse database with high-quality image pairs will yield better results. The size of the extracted patches also influences the level of detail that can be recovered. Larger patches can capture more context but might also introduce artifacts if the database doesn’t contain similar patterns.

Figure 2: Image preprocessing steps for training images. (a) We start from a
low-resolution image and (c) its corresponding high-resolution source. (b) We form an initial interpolation of the low-resolution image to the higher pixel sampling resolution. In the training set, we store corresponding pairs of patches from (d) and (e), which are the band-pass or high pass filtered and contrast normalized versions of (b) and (c), respectively. This processing allows the same training examples to apply in different image contrasts and low frequency offsets.

Figure 3: Image Patches Database
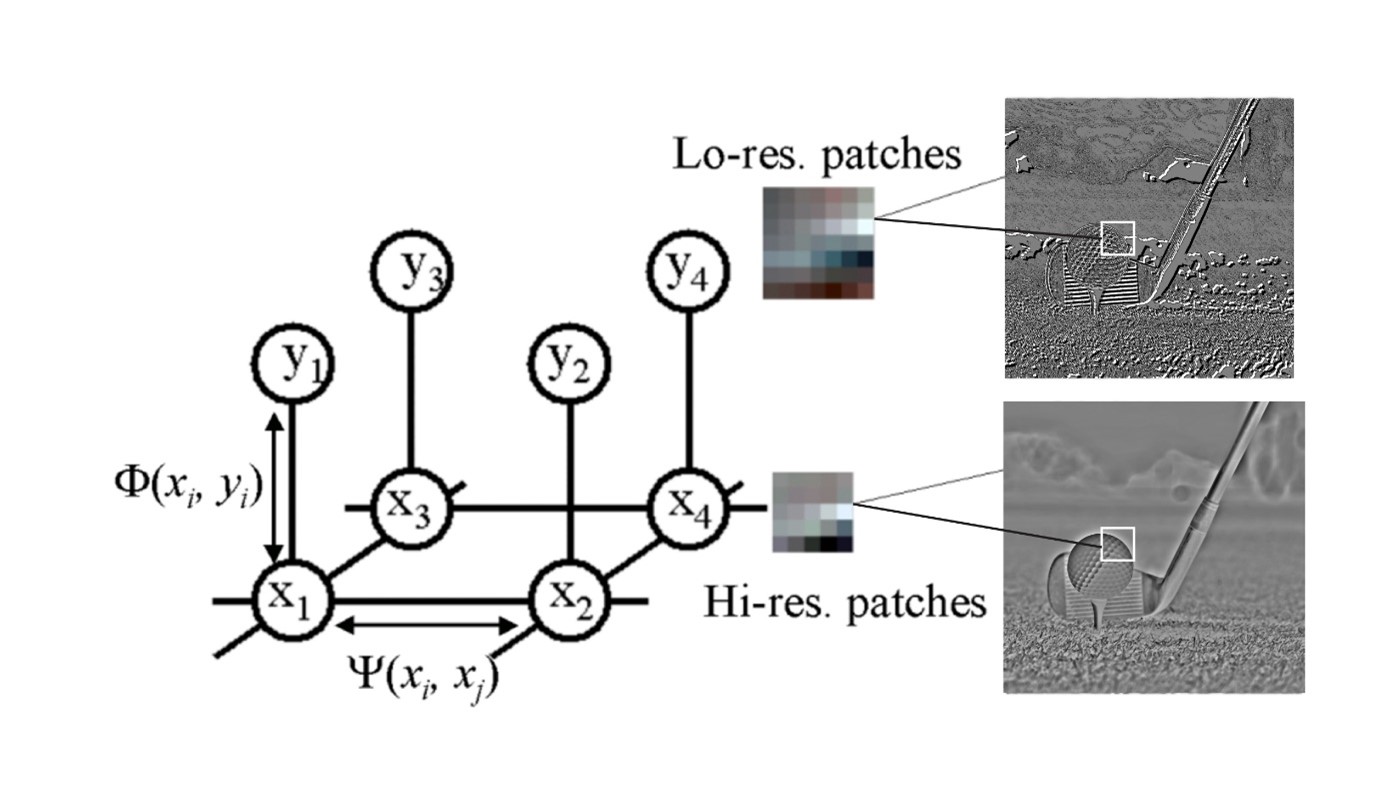
Figure 4: Markov Network Model
This method can be formulated as a Markov network problem. In this framework, we treat each pixel in the high-resolution image as a random variable. The goal is to find the most likely high-resolution image given the low-resolution input and the example database. This is typically solved using belief propagation, or graph cut algorithms.
While Example-Based Super Resolution provides a powerful framework for enhancing image resolution, it’s part of a broader landscape of super resolution techniques. As research in this field has progressed, more advanced mathematical concepts and machine learning approaches have been incorporated to further improve results and efficiency.
One key challenge in super resolution is the efficient representation and reconstruction of high-resolution details from limited low-resolution data. This is where concepts like compressed sensing come into play. Compressed sensing offers a way to reconstruct signals (in this case, high-resolution images) from seemingly insufficient information, which aligns well with the goals of super resolution.
Compressed Sensing
Compressed sensing builds on the idea that many natural signals, including images, have an inherent structure or sparsity that can be exploited. This concept complements the example-based approach by providing a mathematical framework for understanding how much information is truly needed to reconstruct a high-quality image. Compressed sensing exploits the fact that many natural images are sparse in certain domains – meaning they can be represented accurately by a small number of non-zero coefficients.
Images are often compressible in Fourier or wavelet bases. Mathematically, we can express this as:
x = Ψα
Where x is the image, Ψ is a basis (like Fourier or wavelet), and α is a sparse vector of coefficients.
 Figure 5: Data Compression
Figure 5: Data Compression
In super resolution, we can use this sparsity to our advantage. Instead of trying to recover all possible high-frequency details, we focus on recovering the sparse set of important coefficients. This makes the problem more tractable and often leads to better results.
Patch Redundancy
Another key concept in super resolution is patch redundancy. Natural images tend to contain patterns that repeat both within the same scale and across different scales. For example, a brick wall will have similar patches repeating across the image. Even more interestingly, if you zoom into a small part of the wall, you’ll likely find similar patterns at this smaller scale.
This redundancy is powerful because it allows us to “borrow” information from one part of the image to enhance another. In single-image super resolution, we can use larger-scale patches to inform how we enhance smaller-scale patches, effectively allowing the image to serve as its own example database.
Patch redundancy allows us to recover finer details that might be lost in low-resolution images. It also helps reduce the noise and artifacts in the reconstructed image by leveraging the consistency of patterns. It helps preserve and enhance the texture and appearance of the original image.
Image Super-Resolution Using Deep Convolutional Neural Networks
In recent years, deep learning has revolutionized the field of super resolution. Convolutional Neural Networks (CNNs) have proven particularly effective for this task.
Here’s a simplified overview of how a CNN might approach super resolution:
-
-
- Input Layer: The network takes a low-resolution image as input.
- Convolution: Convolution layers extract features from the input image at different scales. In this method, filters are applied to the input to create feature maps. Further, a non-linear activation function (like ReLU) introduces non-linearity into the network. Downsampling operations (e.g., max pooling) are also done to reduce the spatial dimensions while retaining important information.
- Upsampling Layer: This layer increases the spatial resolution of the feature maps, typically using techniques like nearest-neighbour interpolation, bilinear interpolation, or deconvolution.
- More Convolutional Layers: Additional convolutional layers are used to refine the upsampled features and learn complex relationships between the low-resolution and high-resolution images.
- Output Layer: The final layer produces the high-resolution image, often using a sigmoid or tanh activation function to normalize the pixel values.
-
One of the key advantages of CNNs is their ability to learn complex, non-linear mappings between low and high-resolution images. They can capture intricate patterns and relationships that are difficult to model explicitly.
Recent advancements have led to even more sophisticated architectures. For instance, the Hybrid Attention Transformer combines the strengths of CNNs with the long-range dependency modelling of transformer architectures. This allows the model to consider the global context when enhancing local details.
Another interesting development is the use of diffusion models for super resolution. These models work by gradually adding noise to an image and then learning to reverse this process. When applied to super resolution, they can generate highly detailed and realistic high-resolution outputs.
The diffusion index (DI) is a metric used to quantify the quality of super-resolution results. It measures how well the enhanced image preserves the statistical properties of natural images, providing a more nuanced evaluation than traditional metrics like PSNR (Peak Signal-to-Noise Ratio) or SSIM (Structural Similarity Index).
Evaluation Metrics
To quantify the quality of super-resolution results, various metrics are used, including:
Peak Signal-to-Noise Ratio (PSNR): Measures the difference between the original and reconstructed images in terms of mean squared error.
Structural Similarity Index (SSIM): Evaluates the structural similarity between images, considering luminance, contrast, and structure.
Diffusion Index (DI): Quantifies how well the enhanced image preserves the statistical properties of natural images.
Explore e-con Systems High-Resolution Cameras
e-con Systems comes with 20+ years of experience in designing, developing, and manufacturing OEM cameras. We recognize embedded vision applications’ high-resolution camera requirements and build our cameras to best suit the industry demands.
Take a look at 20MP (5K) cameras developed by our expert engineers – 20 MP (5K) Cameras Or visit our Camera Selector Page to explore out end-to-end portfolio.
We also provide various customization services, including camera enclosures, resolution, frame rate, and sensors of your choice, to ensure our cameras fit perfectly into your embedded vision applications.
If you need help integrating the right cameras into your embedded vision products, please email us at camerasolutions@e-consystems.com.

Prabu is the Chief Technology Officer and Head of Camera Products at e-con Systems, and comes with a rich experience of more than 15 years in the embedded vision space. He brings to the table a deep knowledge in USB cameras, embedded vision cameras, vision algorithms and FPGAs. He has built 50+ camera solutions spanning various domains such as medical, industrial, agriculture, retail, biometrics, and more. He also comes with expertise in device driver development and BSP development. Currently, Prabu’s focus is to build smart camera solutions that power new age AI based applications.